Finely Parsing the Corpus
by Kris Shaffer
Now that we have a small collection of song files that combine the IPA text and music in one place, we can start to look in detail at the relationship between the musical and lyrical structures. For that, we created the parseFullData.py script. This script uses a combination of music21 functions and our own custom text-analysis functions to parse each song note-by-note and provide detailed information about each note's musical properties (pitch, duration, beat placement, etc.) and lyrical properties (for now, simply whether or not the syllable is stressed, and where the vowel sound falls on the open–neutral–close scale). This produces a really big table, with a lot of information:
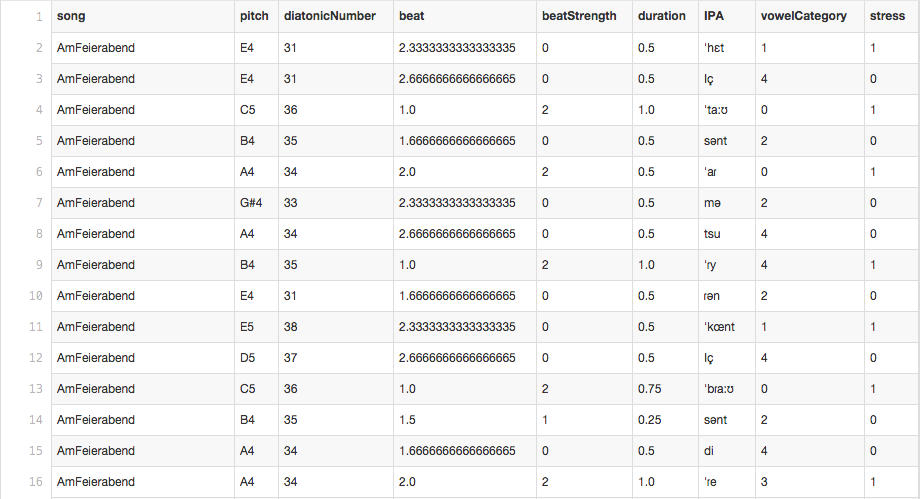
etc.... (It also produces a table for each song in the corpus individually.)
This output is where I'm starting to have some fun. I started learning the statistical analysis program R this summer, and it can do some really powerful things with this output. I can import this data into R with a single line of code, and then ask all kinds of really specific questions ... and get the answers very quickly. Things like:
- What is the most common vowel category? — in the whole corpus? in each song?
- Is there a correlation between a syllable's stress and what part of the beat it falls on? (there is)
- Is there a correlation between the "openness" of a vowel and how high the note is? how long the note is? what beat the note falls on?
...and so on.
For now, I've just been asking R random questions about the corpus and getting mixed results. Next, I'll write an R script that will systematically ask these questions of all the songs in the corpus, so we can do some good "distant reading" of the corpus and get a feel for what's going on, and in which songs are the most interesting things happening.
If you use R, feel free to download the data, import it yourself, and play around. Let us know if you find anything cool!
